





NACE Journal, May 2019
A study conducted at Ohio University shows the power and potential of machine learning to predict and influence employment at graduation.
Grace took a deep breath as she finished her last career coaching session. It had been a packed schedule of appointments, mostly with students visiting the career center for the first time. To wrap up the day, she turned to the university’s student success analytics software. The newest and most novel feature of the platform is a dashboard that uses machine learning to predict student career outcomes. Grace uses it to identify students likely to graduate without a job offer—enabling her to intervene early and often.
In the past, Grace may have caught students graduating without a job offer when they were seniors, frantically searching for any job opportunity. Now, she can identify students who are likely to graduate without a job as early as freshman year—and encourage them to engage in academic programs or work experiences that increase their likelihood of graduating with a job.
Data analytics versus machine learning
- Data analytics is the process of describing data using basic statistics to draw conclusions.
- Machine learning is a form of artificial intelligence that extracts insights from data through pattern recognition to predict future outcomes.
Grace pulls a report from the dashboard on sophomore marketing majors predicted to not have a job at graduation. The analysis highlights that many of these students have yet to participate in a co-curricular activity. She will e-mail this group of students in the morning, encouraging them to make an appointment and noting that co-curricular involvement, such as joining the American Marketing Association, is not only an opportunity to explore various career options, but also a signal that employers look for to gauge leadership and teamwork potential. By connecting with these students as sophomores, Grace can get them on the path to full-time employment before graduation.
In the past month alone, she met with dozens of students who looked like they wouldn’t have a job and guided them toward activities that improve their chances of finding one. Through her interventions, those students are now seeking internships, joining student organizations, and considering certificates as measurable steps to boost their employability.
The new dashboard leverages existing, accessible data, e.g., major, GPA, co-curricular activities, and internships, but analyzes it in a new way—through machine learning. The insights that predict employment are invaluable as Grace strives to provide the best possible career coaching support to her students.
The Power of Predicting Employment
This scenario illustrates the role that machine learning, a form of predictive analytics, can play in supporting student career outcomes. Fueled by lawmakers, policy advocates, and parents, much of society now views higher education as the primary means to an entry-level job.1 As a result, universities are increasingly held accountable for career outcomes—making it a priority for career centers to identify effective and scalable approaches for student career management.
The ability to predict which students will and will not be employed—and why—enriches career coaching by identifying the individuals in need of support and tailoring guidance to help them. Career outcome predictions can inform career coaches on precisely how many internships, exactly how many co-curricular activities, what specific types of activities, and which majors are most likely to lead to a job offer—and how all of those factors work together.
While this may sound like a far-off future, predicting a student’s employment is happening today. A recent study at Ohio University (OHIO) leveraged machine learning to forecast successful job offers before graduation with 87 percent accuracy. When someone asks the right questions—such as, “If a student has a 3.1 GPA, participates in two co-curricular activities, and completed one internship, will he or she be employed?”—we now have an approach to find the answer.
Career Center Data and Machine Learning
Career centers are inundated with data—appointment history, recruiting details, employer engagement, resume data, and first-destination survey results. For many of us in career services, compiling and reviewing this massive pile of information with data analytics is the new normal. We use it to answer basic questions, such as “How many people came to the career fair?,” “What percentage of our appointments were juniors?,” and “What are our positive outcomes?”
If time permits, we may dig deeper to answer more complex questions, such as “Who are our top employers by hires and engagement?” and “How many students interned last summer?” In short, we use data to describe what is happening in our career centers.
However, just as we have begun to adapt to the new normal of data analytics, the game is changing. One rapid advancement is machine learning: a form of artificial intelligence that extracts insights from data through pattern recognition to forecast future outcomes. Machine learning can analyze massive, complex datasets while delivering more-accurate results, faster than we can.
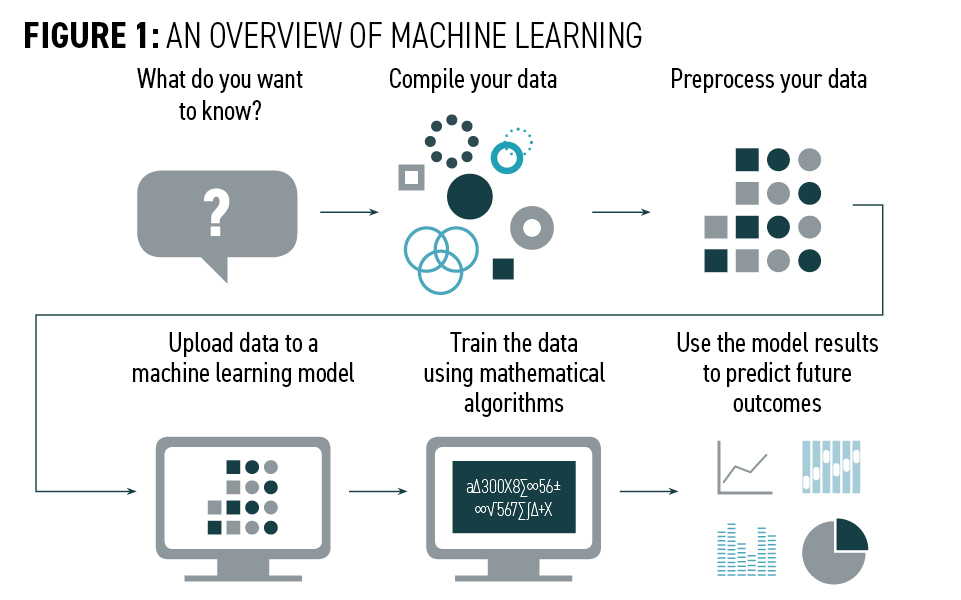
The first step in leveraging machine learning is deciding what you want to learn from your data. Next, you compile and clean the data so they can be analyzed. Then, the data are uploaded to a machine learning model. There are dozens of types of models, each one analyzing the data in a slightly different way through different algorithms. The algorithms “train” themselves by assessing the information thousands of times while looking for patterns. Once the model recognizes patterns, new data can be added to it to predict an outcome that is currently unknown. (See Figure 1.)
The predictive power of machine learning has already become part of our everyday lives, even if we do not always notice it. The technology detects banking fraud, recommends online advertisements, powers driverless cars, and forecasts medical diagnoses. It is inevitable that machine learning will become common in higher education, begging the question: “Can we accurately predict which students will be employed at graduation?”
Predicting Employment With Machine Learning
A study at Ohio University aimed to predict employment by combining the knowledge of university career centers and recruiting with data analytics and machine learning. The study used data from first-destination surveys and registrar reports for undergraduate business school graduates from the 2016-2017 and 2017-2018 academic years. The study included data from 846 students for which outcomes were known; these data were then used in predicting outcomes for 212 students.
This research began with a review of employment and employability signals, which provided a foundation for which data points needed to be included in the study. The research then leveraged machine learning models to determine which students are most likely to be employed at graduation.
The key elements and steps of the study included:
Identifying employability signals: It is well-recognized that employers desire particular skills from undergraduate students, such as a strong work ethic, critical thinking, adept communication, and teamwork. However, in most instances, employers cannot directly evaluate a student’s employability skills. For example, unless an employer is watching a student in a team setting, the employer cannot say if that student has strong teamwork skills.
Therefore, employers rely on employability signals—activities or accomplishments that imply skills. Academic employability signals, such as major and GPA, can signify cognitive thinking and problem-solving whereas experience employability signals, such as co-curricular activities and internships, can suggest leadership, teamwork, professionalism, and work ethic.2, 3, 4, 5 Employers assess multiple employment signals—represented by a student’s academic and experience achievements—to make hiring decisions.6, 7, 8 (See Figure 2)
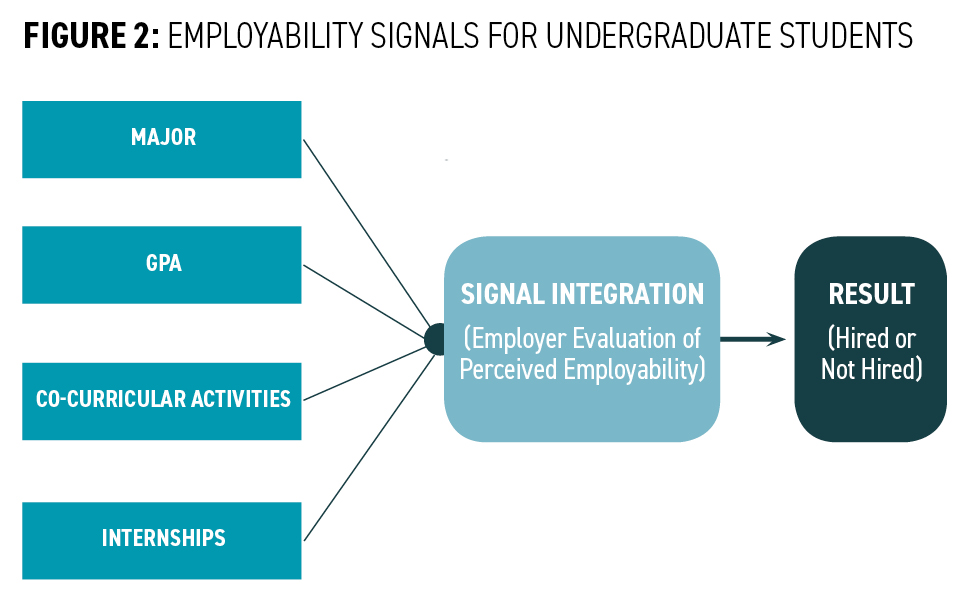
The OHIO research focused on using employability signals to predict employment (a state of being employed) rather than employability (one’s ability to be employed).
Machine learning to predict employment at graduation: The OHIO study examined several past employment prediction studies that used resume audits.9, 10, 11 Resume audit research only has a tangential ability to predict student employment before graduation; basically, students with higher academic achievement and more experiences are considered more employable. Machine learning provides an alternative—and more robust—method of analysis compared to static resume audits.
Few studies to date apply machine learning models to higher education data.12, 13 The OHIO study is the first known instance of machine learning being used to predict career outcomes.
Compiling and cleaning data: As noted above, to predict employment at graduation, the study pulled data from first-destination surveys and registrar reports for undergraduate business school graduates from the 2016-2017 and 2017-2018 academic years.
The machine learning models use past data to recognize patterns, followed by applying new data to predict an outcome—in this case, full-time employment at graduation. Employment at graduation is the most desired outcome for the College of Business; therefore, that was the focus of the analysis rather than just employment. The dataset included GPA, major, number of co-curricular activities, number of internships, sex, ethnicity, international status, graduation date, number of majors, number of selective programs and centers,14 and number of student organizations.
Before analysis, the dataset was cleaned, with missing values addressed and repetitive and extraneous variables eliminated. The study assessed the known history of 846 students to train the model, followed by applying predictions to 212 students.
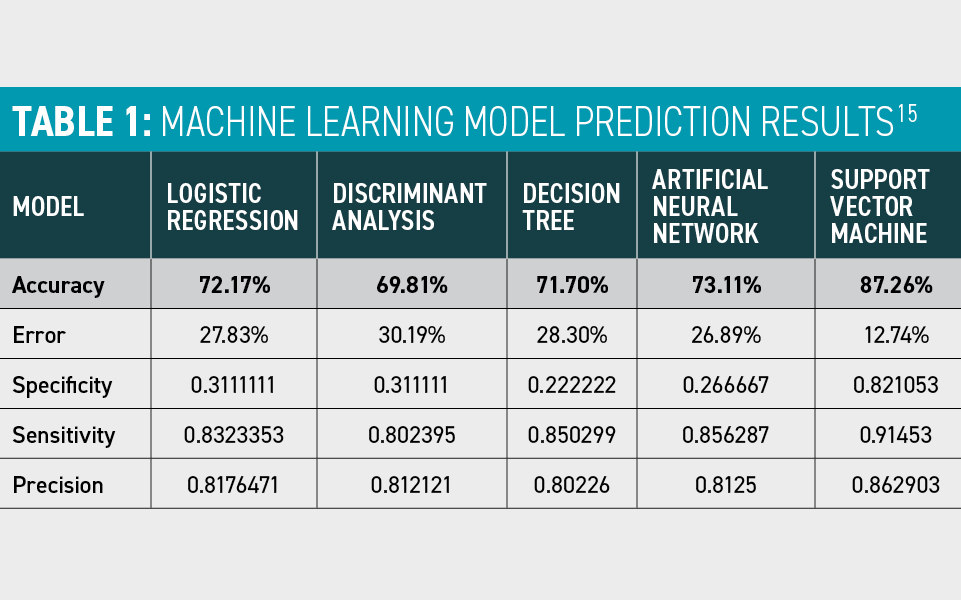
Analyzing the results: The data were used to develop numerous machine learning models, from commonly recognized methodologies, such as logistic regression, to advanced, non-linear models, such as a support-vector machine. Following the development of the models, new student data points were added to determine if the model could predict those students’ employment status at graduation. It correctly predicted that 107 students would be employed at graduation and 78 students would not be employed at graduation—185 correct predictions out of 212 student records, an 87 percent accuracy rate.
Additionally, this research assessed sensitivity, identifying which input variables were most predictive. In this study, internships were the most predictive variable, followed by specific majors and then co-curricular activities.
Implications for Higher Education
Given that no other studies have been identified that used machine learning to predict the employment of undergraduate students, this research provides a critical first step to analyzing readily accessible career center data with machine learning models. Datasets similar to the one used in this study are available at many colleges and universities. Therefore, any university looking to understand employment before graduation can adapt this approach to their institution. Moreover, this study serves as a first step to research using large datasets to gauge employability on a much broader scale, beyond the confines of a single university or school within a university.
The study demonstrates that employment can be predicted through a machine learning model, which will have significant impacts on institutions seeking to understand and improve student employment outcomes.
In an age when colleges and universities are expected to facilitate positive outcomes for students, machine learning could be the key to tailored and targeted insights. Career coaches who are empowered with the knowledge of which students are expected to obtain employment can focus their limited time and energy on those requiring support. Moreover, an understanding of why students in specific programs, colleges, or universities are employed will enable coaches to provide more specific recommendations—steps that have been proven to land students a job.
As university career centers consider developing predictive models, there are the following steps to consider:
Ask questions: Any analytics effort begins with a question, from more simplistic queries, such as “How many students will have internships next summer?,” to the complex, e.g., “Are students satisfied with their chosen industry?” Continuously asking questions of your data provides the foundation for both data analytics and machine learning.
Compile data: Compiling data requires an understanding of what data you need and different sources for procuring that information. For example, the OHIO study focused on a small number of data points that were easily accessible from the first-destination survey and the registrar’s office: major, GPA, co-curricular activities, and internships. But several variables could be added to the analysis. For example, performance in specific classes, resume quality, the number of appointments with the career center, the number of career fairs attended, and data from personality assessments could be assessed, among other pieces of information. Additional variables would enhance the predictive power of the machine learning models and provide context for significant variables.
Additionally, the research specifically focused on College of Business students; however, universities can choose from institutional-level, college-level, and major-level subsets of students. Each subset will likely produce slightly different results. The analysis of data from the institutional, college, and major levels will produce the best understanding of employment across an entire higher education institution.
Develop models: The process of machine learning requires the patience to test models repetitively so that the model can learn. Small changes to the data or the model can result in drastically different outcomes. The more data a machine learning model intakes and the more times it runs, the more accurate it becomes. The OHIO study demonstrated that some models are more predictive than others, demonstrating the need to evaluate multiple models—more-complex data benefit from more-complex models. (See Table 1.)
To develop these models, career centers can leverage talent within the institution—faculty and staff with advanced analytics skills. Alternatively, colleges and universities may seek out analytics experts in the field familiar with analyzing higher education data.
Analyze the results: It is essential to understand the results in context. Often, these types of studies are led by staff in an office of institutional research or by an expert in machine learning methods, neither of whom may have contextual information regarding career center data. A strong understanding of the data from career center practitioners can provide nuanced insights into the results of a machine learning model—and potentially influence its predictive ability.
The Future of Career Center Data and Machine Learning
Predicting outcomes with career center data is still in its infancy. The research is complex and somewhat cumbersome due to the vast amount of data requiring analysis and the newness of applying higher education data to the models. Nevertheless, there are vast opportunities to predict outcomes in employment and beyond, including student satisfaction, time to graduation, retention, and more. The possibilities are endless, and leveraging machine learning within university career centers is a natural starting point.
Endnotes
1 Selingo, J. (2016). There Is Life After College: What Parents and Students Should Know About Navigating School to Prepare for the Jobs of Tomorrow. New York, NY: HarperCollins.
2 Cai, Y. (2013). Graduate employability: a conceptual framework for understanding employers' perceptions. Higher Education, 65(4), 457-469.
3 National Association of Colleges and Employers. (2017). The Key Variables Employers Seek on Students’ Resumes. Retrieved from https://www.naceweb.org/about-us/press/2017/the-key-variables-employers-seek-on-students-resumes/.
4 Nemanick, R. C., & Clark, E. M. (2002). The differential effects of extracurricular activities on attributions in resume evaluation. International Journal of Selection and Assessment, 10, 206–217.
5 Rothman, M. & Sisman, R. (2016). Internship Impact on Career Considerations Among Business Students. Education & Training, 58(9), 1003-1013.
6 Cai, Y. (2013).
7 Chronicle of Higher Education. (2012). The Role of Higher Education in Career Development: Employer Perceptions. Retrieved from https://chronicle-assets.s3.amazonaws.com/5/items/biz/pdf/Employers%20Survey.pdf.
8 National Association of Colleges and Employers. (2017). Intern Offer, Acceptance Rates Indicate Robust Market. Retrieved from https://www.naceweb.org/talent-acquisition/internships/intern-offer-acceptance-rates-indicate-robust-market/.
9 Nemanick, R. C., & Clark, E. M. (2002). The differential effects of extracurricular activities on attributions in resume evaluation. International Journal of Selection and Assessment, 10, 206–217.
10 Nunley, J. M., Pugh, A., Romero, N., & Seals, R. A. (2016). College major, internship experience, and employment opportunities: Estimates from a résumé audit. Labour Economics, 38, 37-46.
11 Pinto, L. H. & Ramalheira, D. C. (2017). Perceived Employability of Business Graduates: The Effect of Academic Performance and Extracurricular Activities. Journal of Vocational Behavior, 99(2017), 165-178.
12 Durdevic Babic, I. (2017). Machine Learning Methods in Predicting the Student Academic Motivation. Croatian Operational Research Review, 8(2), 443–461
13 Schumacher, P., Olinsky, A., Quinn, J., & Smith, R. (2010). A Comparison of Logistic Regression, Neural Networks, and Classification Trees Predicting Success of Actuarial Students. Journal of Education for Business, 85(5), 258–263
14 The College of Business has several exclusive co-curricular programs and centers that require students to apply for acceptance. For example, these include the honors program and Schey Sales Centre, which accepts students into the program and requires additional coursework and co-curricular experiences.
15 The Ohio University study tested five machine learning models to identify the most accurate predictor of outcomes. While all performed with a reasonable degree of accuracy overall, the support vector machine model far surpassed the others.


